Semantics is the study of words, and relationships between them and how we interpret them to derive meanings. Different words, and word and sentence constructions can be interpreted differently by different people depending on the context. The word indraśatru, for example, could be interpreted in two ways – Indra’s killer or he-who-is killed-by Indra. In Vedic Sanskrit, accents would have saved the day, but in Classical Sanskrit, it is only the context that can inform us what the meaning is.
Semantic analysis is the process of taking a piece of text of the language and relating it to its basic language-independent meaning. Let us say you have in your mind the picture of Ravana dying. If your language is English you would say, ‘Ravana died’. In Hindi you would say, ‘Rāvaṇ mar gaya’; In Sanskrit you would say ‘rāvaṇo mr̥taḥ’ etc. Semantic analysis involves taking the sentence in, say, Sanskrit, and analyzing it to arrive at the picture of Ravana dying. And if you took the other languages, even though the words and the sentence are different, you have to arrive at the same picture. If you analyzed the texts of the languages semantically correctly, you would get that picture.
Depending on who you are, the word die, marna or mr̥ is etched in your mind as a basic word. But suppose in English you were to say ‘Ravana passsed away’, or in Hindi, ‘Ravan eswar ke pas gaya (he went to God)’. and in Sanskrit Rāvaṇaḥ pañcatvam āgamat ‘he came to the five elements’.
Now, how do you get to the fact that ‘Ravana died’ from these different phrases? These three sentences all have the idea of coming or going, and the syntactic context of the words away, god, or five elements can point you to the idea of death. Also, there may be a semantic context before this sentence, where Rama has been shooting arrows at Ravana, or context after, where somebody is cremating Ravana’s body. To get a semantic sense that is independent of the language you will need to use all these cues and contextual pointers.
So, semantic analysis is understanding the context of roots, words, phrases, idioms, figurative speech, sentences, paragraphs etc., and relating each of these to the text as a whole to understand the import of the text. There may be also cultural contexts. In many parts of India, when somebody is leaving, they are apt to say “Shall I come?” instead of “Shall I go?”
And the three sentences: you killed him, you killed him!, and you killed him?, have three different meanings. These nuances also need to be brought in when doing semantic analysis. [Of course, one thing we cannot bring into semantic analysis of texts, is nuances of meaning based on tone of voice, facial expressions etc. Let us leave that aside.]
You also have to deal with words and phrases having different meanings in different contexts, and rhetorics like similes and metaphors.
One important thing is to know the domain in which the text appears. This will allow the analyst to have a specific kind of expectation of the words and meaning that can arrive. The same word ‘goal’ used in the context of a football match will have a different meaning than when used in the context of a business presentation.
Another area to know about when doing semantic analysis is alignment of certain words. Some words tend to appear near each other giving a specific meaning to the combination and to the separate words.
Interestingly, there were a set of grammarians in India who worked with Classical Sanskrit to make sense of exactly these kinds of situations. The approach of this school of grammarians was to look at language constructions independent of the words used, and of the syntax. That is, their approach starts the analysis of a sentence from the semantic (rather than the syntactic) values of it.
In 1985, there appeared a paper entitled “Knowledge Representation in Sanskrit and Artificial Intelligence” in the journal, AI Magazine, Volume 6 Number 1. It was authored by Rick Briggs of the Research Institute for Advanced Computer Science of the NASA Ames Research Center. In it, Briggs argued that natural languages can serve as well as artificial languages for representing knowledge. He uses Sanskrit as an example of a natural language that can be used for this purpose. His logic was based on the fact that Sanskrit grammarians had a “a method for paraphrasing Sanskrit in a manner that is identical not only in essence but in form with current work in Artificial Intelligence.” [‘Current’ is, of course, 1985]. He says that “One of the main differences between the Indian approach to language analysis and that of most of the current linguistic theories is that the analysis of the sentence was not based on a noun-phrase model with its attending binary parsing technique but instead on a conception that viewed the sentence as springing from the semantic message that the speaker wished to convey.” His main references for this are Sanskrit grammarians of the 17th and 18th century, mainly Bhattoji Dikshita, Kaudabhatta and Nagesha.
In his abstract he says that in the paper, “a typical Knowledge Representation Scheme (using Semantic Nets) will be laid out, followed by an outline of the method used by the ancient Indian grammarians to analyse sentences unambiguously. Finally, the clear parallelism between the two will be demonstrated, and the theoretical implications of this equivalence will be given”.
This well-researched and well-written paper was published during the early years of progress in AI. It was part of the AI fraternity’s then efforts at finding the best way to represent knowledge. Unfortunately, there are no follow up papers or any further work published on this subject. Knowledge Representation techniques and schemes have advanced a lot since then. No current widely prevailing schemes are based on natural languages (however. schemes like Semantic Nets are still used or knowledge representation and retrieval).
One important thing we can learn from this paper is that research into languages and grammar, syntax and semantics was being actively done in India even in the 17th and 18th centuries, and very substantial results were being published.
I have not been able to get a translation of Nagesha’s work, so I am going by what Briggs has stated in his paper.
As we saw before. the approach of Nagesha and the others of his school was to look at language (in their instance, Sanskrit) as constructions independent of the words used and independent of the syntax. That is, the approach starts the analysis from the semantic (rather than the syntactic) values of a sentence. They would for example, take the sentence ‘Rama eats an apple’ and analyse it to arrive at a semantically unambiguous representation of it by paraphrasing it as: ‘There is an activity which leads to a connection activity which has an agent no-one other than Rama, specified by singularity, which is taking place in the present, and which has object something not different from apple.”
Though the concept of a semantic net as a way of representing knowledge was not available to the Sanskrit grammarians, Briggs has shown the equivalence between their approach and semantic nets. Hence, we can use semantic nets to show how they went about their model.
A semantic net uses nodes to represent concepts in the world, and links to represent the relationships between these concepts. The main idea is to create a representation of the meaning independent of the words used. The other idea is to eliminate the interference of syntax. For example, the sentences, ‘John gave a ball to Mary’ and ‘Mary was given a ball by John’ are semantically the same though the syntax is different. So, if we take an example of an event as ‘John gave a ball to Mary’, we get the following figure as a possible semantic network representation.
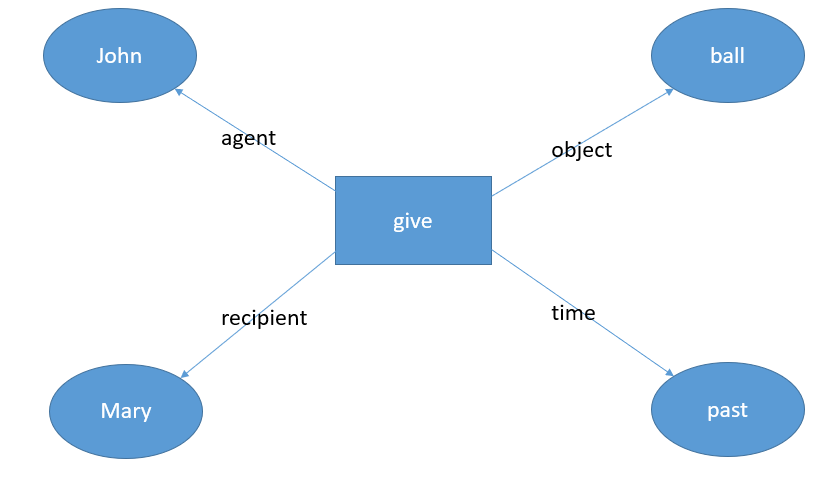
Algebraically, this network can be represented as a series of triplets:
give, agent, John
give, recipient, Mary
give, time, past
give, object, ball
Note that the past tense is indicated by the triplet which talks of the time of action as past.
If we expand the idea of semantic understanding of this sentence further, we can think of this as an action ‘give’ with many supplemental activities. We would mentally associate many pictures in our mind when we read this sentence: John holding a ball in his hand, the movement of the ball from John’s hand to Mary’s hand, the grabbing of the ball by Mary’s hand etc. Of course, we can split these further into the act of John opening his hand, Mary opening her hand etc. etc. Once we have this type of a representation of the knowledge, replacing the word ‘give’ with ‘donate’ would not make any difference, or replacing the sentence with passive also would not make a difference.
I do not know enough to go into details here, but my understanding is that the approach of Nagesha and the other grammarians of this period was to formulate a method of analysis that was logically equivalent to semantic network representation. The representation of ideas in their approach would start from the root of a verb and work all its way up to the sentence, adding derivations from the root, declensional endings, conjugational endings etc. to make sure that the meaning is truly independent of the syntax and the words.
Note that there is nothing inherent in the language (Sanskrit) that asks for this kind of analysis. Other languages like Greek or Latin (and indeed, English that we used before) would have yielded to the same sort of analysis. [Can an isolating language like Chinese yield to this type of analysis? I am not sure.]
The grammarians used Sanskrit because that was the language of literary discourse available to them at that time.
However, unfortunately, this one paper by Briggs has given rise to questionable claims of Sanskrit being “the ideal language for computers”, “best language for Science”, “NASA has acknowledged the greatness of Sanskrit for AI” “Sanskrit is the most suitable language for computing techniques”, “Sanskrit is considered the best language for computer software” “Sanskrit enables scientific ideas to be expressed with great precision, logic and elegance” etc. etc. All such claims can be traced back ultimately to this one paper, though the conclusions of this paper do not imply the facts of any of these claims.
Natural languages are evolving. And as they evolve, they tend to pick up irregularities and exceptions. Some natural languages either become more complex as they evolve or become simpler as they evolve. It is sometimes difficult to describe a language completely and hope that this description will stay true after a hundred years. This is what makes it difficult to use natural languages for formal representations.
One advantage that Sanskrit has over other natural languages is that Sanskrit stopped evolving once it became Classical Sanskrit. Vedic Sanskrit evolved into the various natural languages of North India through the Prakrits. Classical Sanskrit which became “Sanskrit” for discourses and literature stopped evolving and was held constant by Pāṇini’s grammar. Even conversational Sanskrit (where it was used) followed all the rules and styles of Classical Sanskrit. The language was not allowed to evolve naturally. This gave it a stability that allowed the above grammarians to parse and formulate these rules that held for many centuries. However, this still does not make Sanskrit “the best suited for AI” or make any of the other claims true.
There are many other claims: “Sanskrit has a context free grammar”, Sanskrit is a context-based language”, “Sanskrit did not evolve. It was designed.” etc. All these claims are also, on first look, without any basis.
[Note: The question is, how does one test the validity or otherwise of such claims? Most of the claims are those of assigning a potential scientific explanation for ancient statements, myths etc. An example would be the claim that story of the birth of the 100 Kauravas was an ancient case of in-vitro embryology. Other claims tend to go in the opposite direction and assign a total lack of science or mathematics to the ancients.
Again, there are claims of antiquity or non-antiquity of certain works. Sometimes these claims and counter-claims are caught in the web of the interests of special groups.
We need to create a school of analysis that does precisely this testing. The school needs to evolve the necessary tools and methodologies to test claims made on either side and be able to pass an objective judgement on the issue. The tools and methodologies need to chosen with a lot of care. It is important to notice that some of the ancient pronouncements may not yield to a probe by the scientific method as is understood now, mainly because of the lack of availability of previous experimental data. So, the scientific method needs to be modified and adjusted to cater to these ancient paradigms.]

Very enlightening paper.